I facing memory issues with a DHIS2 v2.37.8. I have an event program deployed and I’m experiencing a huge memory consumption on my tomcat container. I moved from a shared server to a dedicated one and nothing changed. It seems to happen when the users a submitting data on the web version.
Welcome back to the community! Please share the logs (without sensitive info) and as much detailed info about the issue as possible. How’s the consumption experienced? How is it affecting the users? How is the event program configured that’s making it different from other event programs? …etc
If we can reproduce the issue or know exactly what the cause is, it will be easier to find a solution.
In my understanding, there’s no special configuration of the event program. But when a non a super user logs in I experience a memory increase also happens when they submit data. the memory goes up until the container stop responding.
Please find the logs in the attached file. logs.docx (154.7 KB)
I see in the log it says: * WARN 2022-11-01T15:51:25,284 Cannot get users with disjoint roles as user does not have any user roles (DefaultUserService.java [localhost-startStop-1])
Please check that the non-superuser has at least one role assigned to them
I also see this log which might be significant as well → “Local Cache (forced) instance created for” [something] (a trillion times) … which is superseded with:
Using legacy cache name [org.hibernate.cache.internal.StandardQueryCache] because configuration could not be found for cache [default-query-results-region].
Update your configuration to rename cache [org.hibernate.cache.internal.StandardQueryCache] to [default-query-results-region]
I’m not sure about this one but please check first by giving the user a role and if it doesn’t work we can ask the backend core software team.
I’ve done a simple with the published container for the same version and I had the same behavior.
link: docker pull dhis2/core:2.37.8-tomcat-9.0.27-jdk11-openjdk-slim
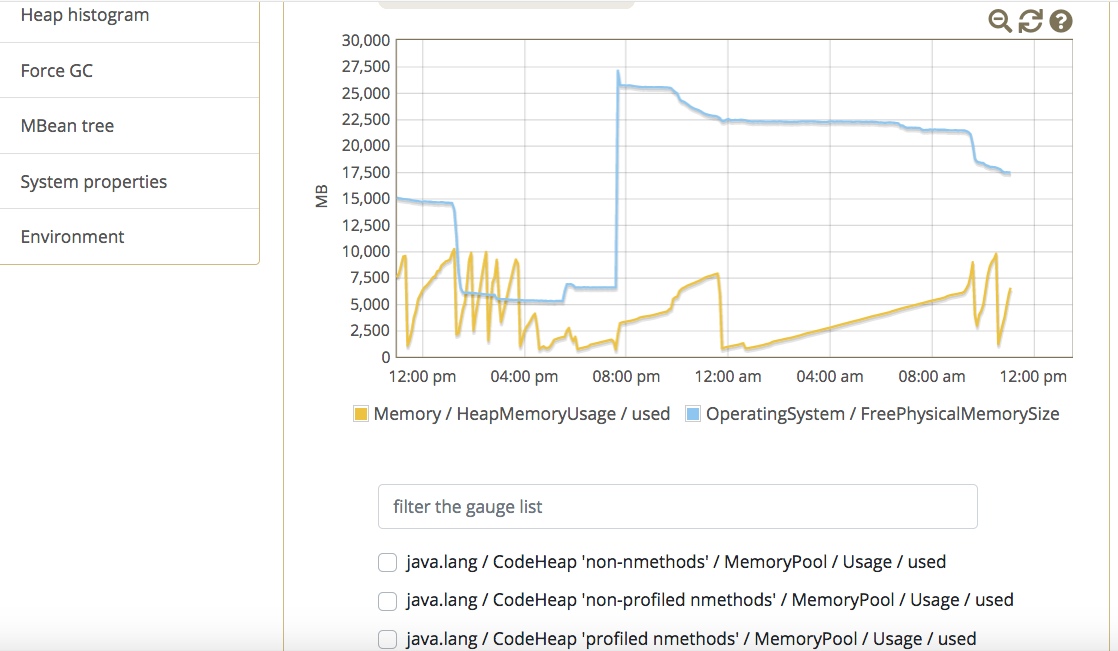
During my database debugging I realized that the system is running a query that takes too long and memory consumption every time I start the container. Can someone tell me the main purpose of the query?
select programsta0_.programinstanceid as program11_192_0_, programsta0_.programstageinstanceid as programs1_192_0_, programsta0_.programstageinstanceid as programs1_192_1_, programsta0_.uid as uid2_192_1_, programsta0_.code as code3_192_1_, programsta0_.created as created4_192_1_, programsta0_.createdbyuserinfo as createdb5_192_1_, programsta0_.lastUpdated as lastupda6_192_1_, programsta0_.lastupdatedbyuserinfo as lastupda7_192_1_, programsta0_.createdAtClient as createda8_192_1_, programsta0_.lastUpdatedAtClient as lastupda9_192_1_, programsta0_.lastsynchronized as lastsyn10_192_1_, programsta0_.programinstanceid as program11_192_1_, programsta0_.programstageid as program12_192_1_, programsta0_.attributeoptioncomboid as attribu13_192_1_, programsta0_.deleted as deleted14_192_1_, programsta0_.storedBy as storedb15_192_1_, programsta0_.duedate as duedate16_192_1_, programsta0_.executiondate as executi17_192_1_, programsta0_.organisationunitid as organis18_192_1_, programsta0_.status as status19_192_1_, programsta0_.completedBy as complet20_192_1_, programsta0_.completedDate as complet21_192_1_, programsta0_.geometry as geometr22_192_1_, programsta0_.assigneduserid as assigne23_192_1_, programsta0_.eventDataValues as eventda24_192_1_ from programstageinstance programsta0_ where programsta0_.programinstanceid=1 order by programsta0_.executiondate, programsta0_.duedate
There’s a big frame of data that the system just stops responding.
Do you have large volumes of events in your database? If yes, then the culprit is “program rule engine” that runs in the backend.
The program rule engine in the backend is not optimised and it fetches all the corresponding event records for a program for which an event has been entered into the memory. If there are large volumes of events in the database, then the server instance quickly runs out of memory and the tomcat crashes.
One way to overcome this is to disable the program rule execution that run in the backend by adding the below flag in dhis.conf file.
system.program_rule.server_execution = off
@Gassim I can provide more technical details if the dev team needs it.
My server stable for 48 hours after adding the flag to dhis.conf. Thank you for the support.
Though I noticed one error .This error occurs when all data entry personnel are entering the data and manager perform event report generating task. Error is as follows.
Great to know that the solution helped. Please share the logs (without sensitive info) and as much detailed info about the issue as possible to understand the problem.