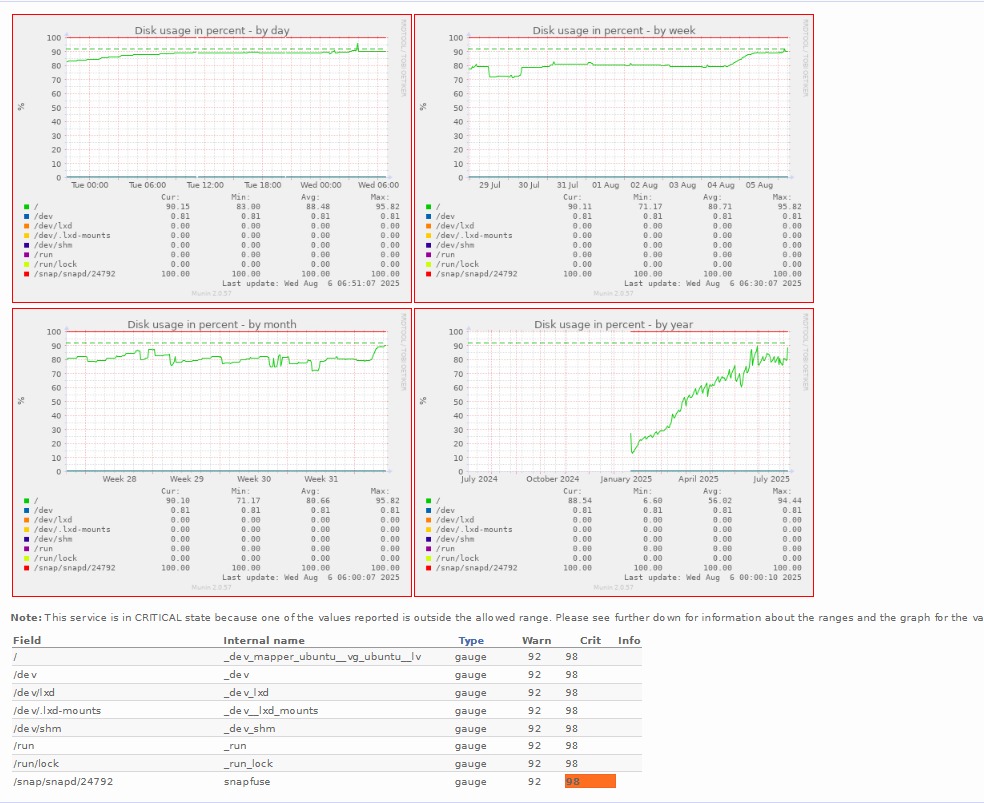
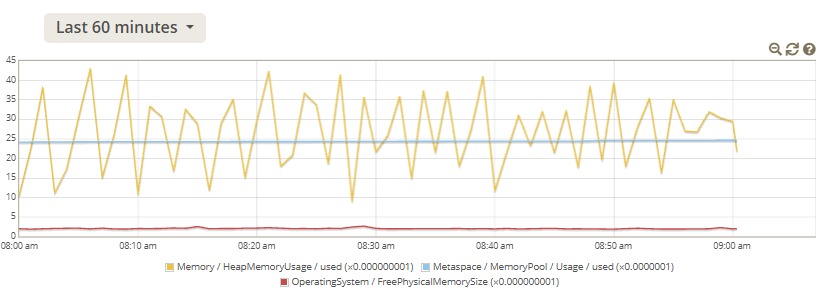
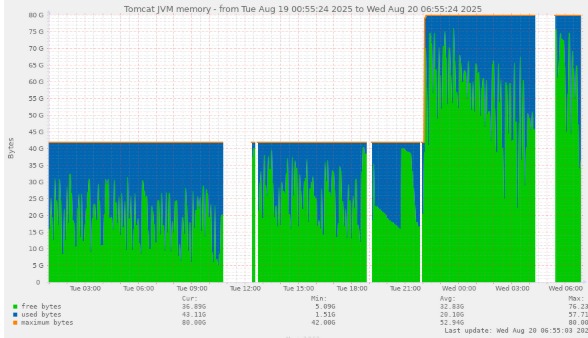
We’re currently running a DHIS2 instance using LXD containers (PostgreSQL, DHIS2 app, Nginx, Munin) on a physical Dell R750xs server with 2 × Xeon 4310 CPUs, 128GB RAM, and 4 × 480GB SATA SSDs in RAID 10. We’ve started seeing severe performance degradation recently with Munin reporting disk usage exceeding 85%, leading to frequent timeouts and other issues. We suspect disk I/O (saturation) may be the main issue.
Has anyone experienced similar issues with containerized DHIS2 setups and disk bottlenecks?
We would love to hear how others have solved this.
Hello Fernando. I can see from munin that your system disk usage has been growing at an unsustainable rate since January. This is a bit more serious than a strictly performance problem. If the disk fills up your database will crash and you will possibly lose data.
It is important to find out what is using all the disk space. Is it just that your database has grown big rapidly or soemthing else is using the disk. For example keeping around lots of daily backups on the server or something similar.
Have you investigated what is using the disk space?