What’s your advice on re-using same data elements in different aggregation datasets in DHIS2.
Is there any bug associated with this? In Data visualizer while selecting data elements we cannot differentiate which dataset it belongs to, we can only select data element and for us it gives a value sum of all datavalues for that data element which is wrong.
Hi Jins,
Yes, it is absolutely recommended to re-use data elements across data sets. It is not a bug that you obtain the sum of all data values when you select a data element. That is exactly what is supposed to happen! Data may be entered say at the facility level, but you may need to calculate a national total. This is the default behavior of DHIS2 and certainly not a bug.
There can be situations however when you need to distinguish between data values entered for the same data element/period/organisationunit combination. An example here might be a data element like “Number of malaria tests performed” which are in turn administered by different implementing partners. In this case, you might have multiple data values for the same facility for the same period. Using an “attribute option combination” you would be able to distinguish between these two values, while also being able to arrive at a single aggregated total.
Maybe you can describe your use case a bit more and we can offer more advice?
Hi @jason Thank you for your reply, I understand this concept you mentioned
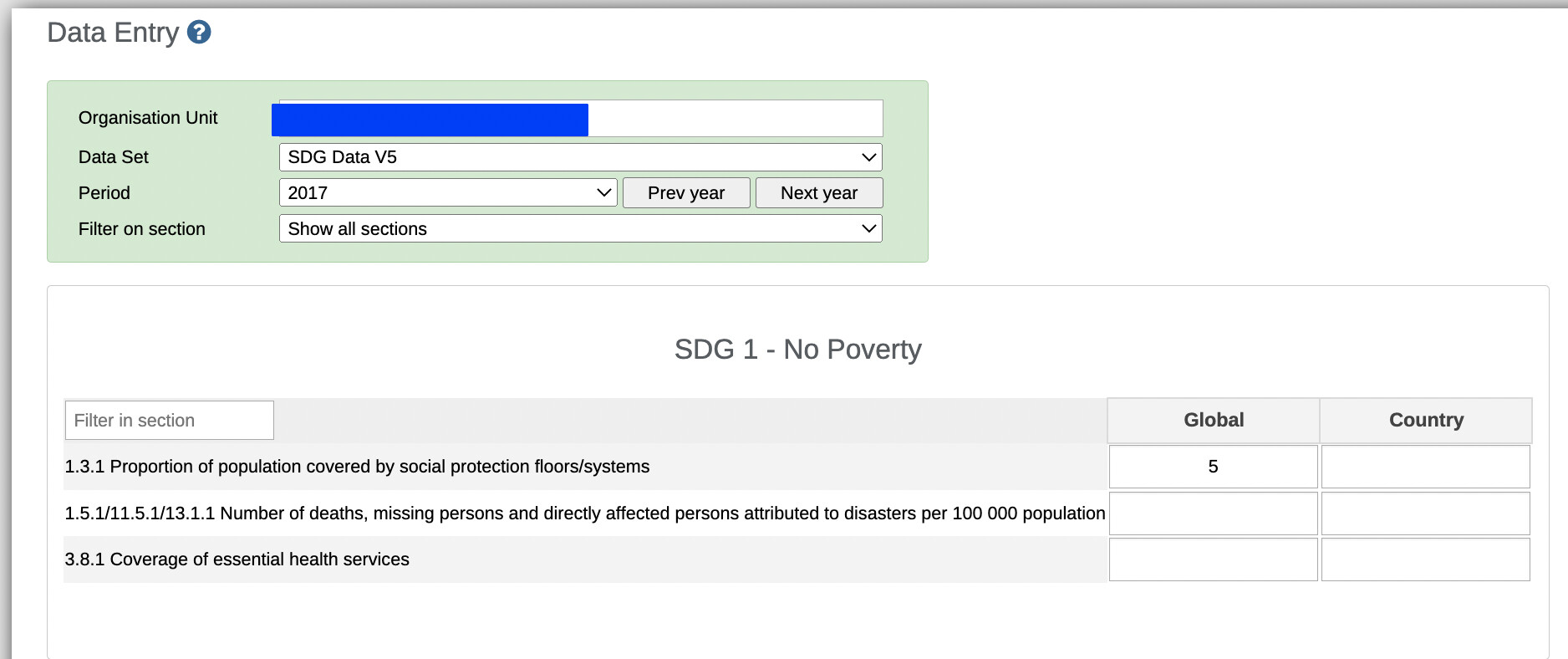
But in my case, it’s still a bit strange, let me explain this, i was trying to re-use data elements from a dataset SDG Data V4 to SDG Data V5, but when i re-used i can already see value 5 which was populated in V4 reflecting in V5 also, I didn’t enter value by myself can that be possible? Please note we we are using category combination Global/Country
That is exactly what is supposed to happen. In the database, there is no direct association between a given data value and a data set. It is only indirectly associated via a data element.
It is not advisable to collect data elements from two different datasets for the same time period and organisation unit. Why would you need to do this since the data has already been collected? It’s just double effort. So, the general philosophy is to “Collect once and reuse many times”, and this is why this data appears. Someone has already entered it into the V4 dataset for the same organisation unit and time period.
There can be situations when you should create a new data element, if you really must distinguish between the two. However, that also bring other complications if you need for instance to compare data over time. I would try and avoid it if possible.
I obviously do not know much about what you are collecting, or how your data is structure, but the use of a category combination like “Global” / “Country” may be problematic. The reason is that by default, DHIS2 will aggregate all category options to a total in the pivot tables. This may or may not be desired in your case. You can configure category combinations so that a total is not produced in analytics, but then you must be very careful in how your pivot tables are designed, as you will need to always use a specific data element/category option in your analysis. It seems to be an unusual design pattern, but perhaps it is what you need in your case.
Thanks @jason it’s getting clear now. So in this case re-using data element for a similar data set is not advisable. Our intention was to refactor the existing data-set, so we had to create a new dataset and try to re-use the data elements for same period, same org units.
I agree on Global/Country design strangeness, we will re-consider this Jason.
But do you also agree that in this case we should not re-use dataelements and create new data elements right.
I think it comes down to whether the data element is representing the same value in both data sets. If the collection methodology has changed, I would say yes,then you should create a new data element since the old values and new values would not be directly comparable. But if they really do both represent the same phenomenon, then I would say to recycle it. If you already have data there from the old dataset, then just instruct data entry personell they do not need to re-enter the data again.