I’m working with a client on defining data elements and disaggregations, and I have a question for anyone with experience on such issues. The requirement is that a certain data element has disaggregations, call them (A, B, C, D). Then A is further disaggregated into A1 and A2. I’m wondering how best to model this. Possibilities include:
Make a single disaggregation category whose options are (A1, A2, B, C, D). Then if I want to see the total for A, I could define an indicator for the sum of data element:A1 and data element:A2.
Define two categories, one with options (A, B, C, D) and another with options (A1, A2, --). Then define a data set section and use “Section grey field management” to eliminate all combinations except (A:A1, A:A2, B:–, C:–, D:–).
Model 2 seems somewhat contrived for this scenario, so I think model 1 is better. Are there any other models I should consider? Or any other wisdom on this?
Wow, that was long ago! We had a few variations on this kind of issue and came up with different solutions for each one. I’ve now forgotten which issue it was I was writing about in this email (before we had a community site but we had an email list.)
Can you say a bit more about what your use case is? That might make it more likely that I’ll give some useful advice.
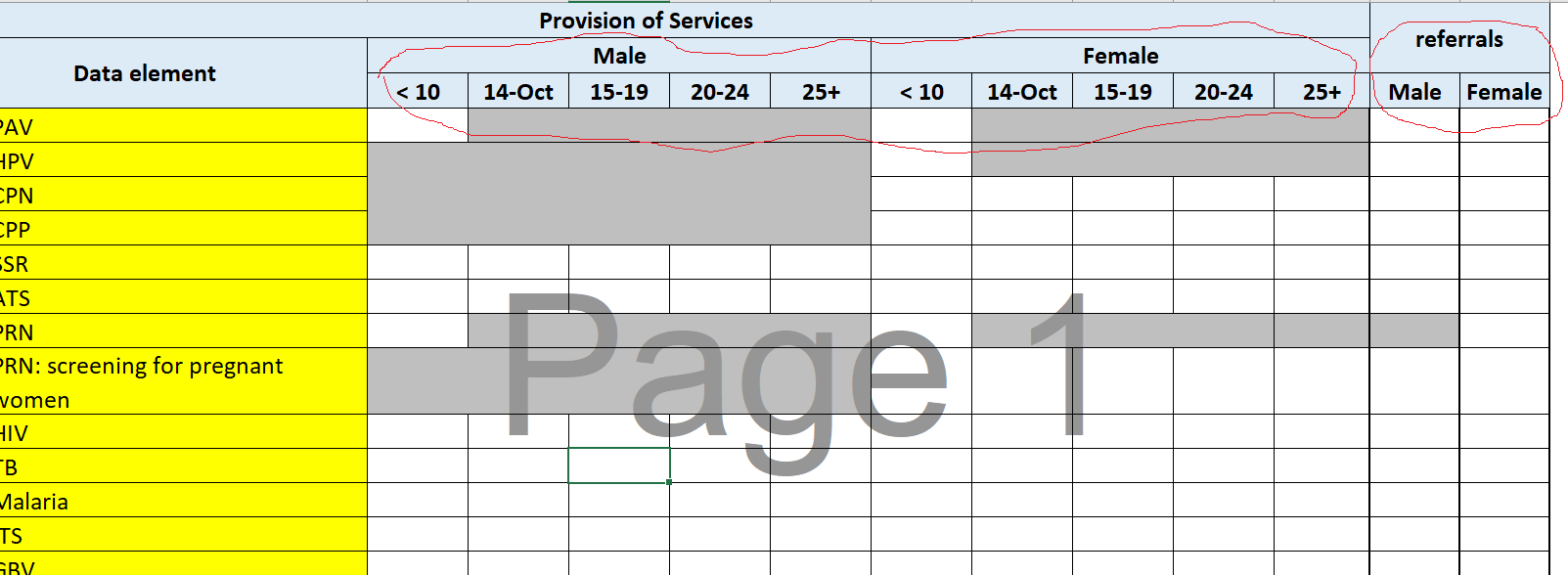
I have two different disaggregation for the same data elements: Gender/Age and referrals/age as shown in the image below. Iam looking for advice on how I can handle this.
Thanks. I think the best answer is to have two data elements for each service type, perhaps ‘PAV service’ and ‘PAV referrals’, or ‘PAV’ and ‘PAV referrals’, etc. The first data element of each type would be disaggregated by gender and age, and the second only by gender. It’s not really possible to enter data for the same data element in the same data set using two different disaggregations.
But I’m guessing that in this case you would want two different data elements anyway, if you are collecting two types of data for each service. If it were possible to have a single data element, then analytics would add them together. For example, if you ask for all the males, you would get the the service data entered for the males summed across the age groups plus the count of male referrals added together. If you need to see these numbers reported separately and not summed in analytics you would want two different data elements anyway.
Thanks for your explanation. Would it make sense to have PAV as data element and have referrals/age as a category combination attached to it? I see it may not be possible as we can not have two DEs with the same name,.i.e. PAV with AGE/SEX as a category combination and another PAV with referrals/age as a category combination.
Yes, you are on the right track. The two data elements for each service would need different names. One would have a category combination of age/sex (2 categories in the combination) and might have a name like ‘PAV provision’. The other would have a category combination of sex (only 1 category in that combination) and might have a name like ‘PAV referrals’.
Question: How are the “provision of service” and the “referrals” related to each other? For example:
(A) Provision of service counts the instances of services provided, whereas referrals provides additional information on whether a referral was involved. These would be reported as two different things in analytics, and should not be added together.
or
(B) Provision of service and referrals together count the instances of services provided. Some of the services provided are counted under the provision of service disaggregations, and some are counted under referrals. In analytics, these would be added together to get the total number of instances of services provided.
Whether the answer is (A) or (B) will affect how you want to set up analytics to report on these values. But in both cases I think you will need two different data elements.