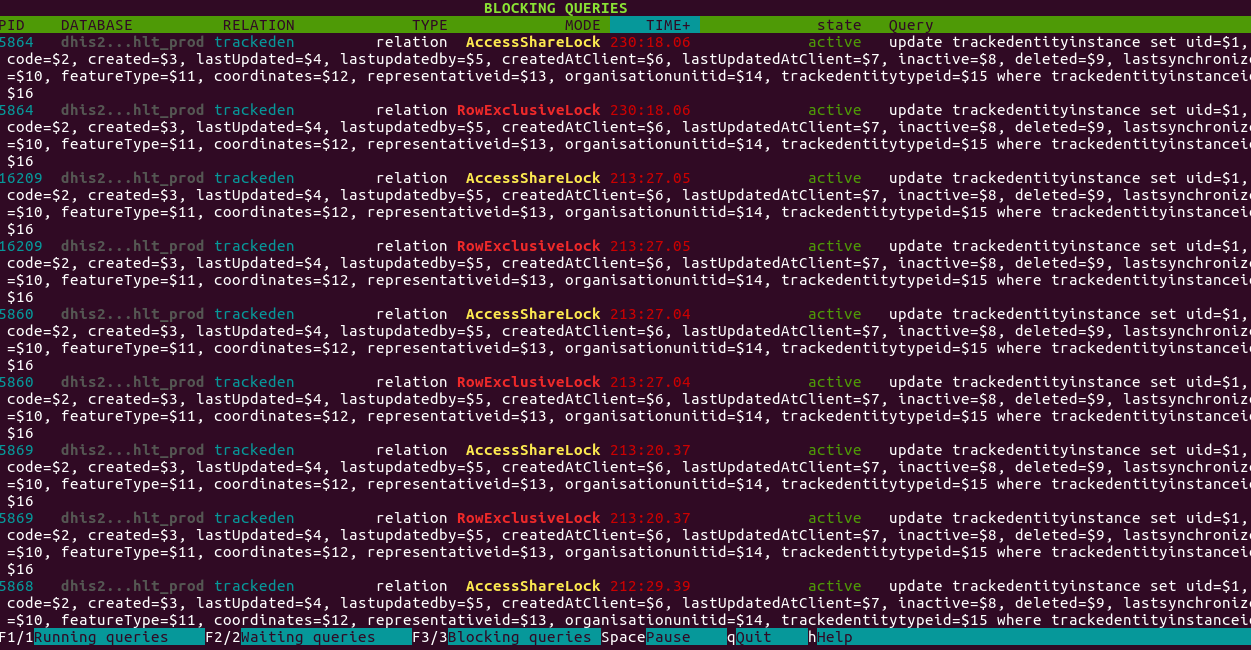
Is it possible that there’s a synchronisation deadlock ? The tablets try to synchronize mulitple program stage instances but linked to the same tracked entity instance ?
or does the user have too much “trackentityinstances” ?
the “updates” and “inserts” of trackedentityinstance seem to last way too long and seem to deadlock
I’ve tcpdumped the network and extracted the body with wireshark,
I’m now able to reproduce that on my server with a curl (without the mobile app).
The payload “looks” trivial in number of instances :
14 trackedEntityInstances
14 enrollment
135 events (so around 10 per entity)
As the nginx logs suggest the request get a http 504 timeout.
The command is run enough you get the symptom where dhis2 looks dead.
I don’t see the dead lock now, but tons of sql running, so assume the “post” ended up in a previous curl. So dhis2 do a lot of select to verify the data matches and conclude nothing should be updated.
but not reaching to that conclusion within 1 minute.
So the user receive “synchronisation” didn’t work but dhis2 is continuing the report… press again “synchronise”… and so on and kills the server or deadlock them self.
does someone can share their numbers ?
what is the biggest tracker ?
should users really be limited to one orgunit to keep this performant ?
does upgrading dhis2 will save the project ?
We’ve tracked this down to the java side doing too much, my hypothesis is that it opens a db transaction but never closes it because it can’t finish on the java side quick enough and just gets swamped with requests and db locks.
We’ve “fixed” this by upgrading our server to have more CPU available, which seems to help a lot, but this will not scale endlessly.