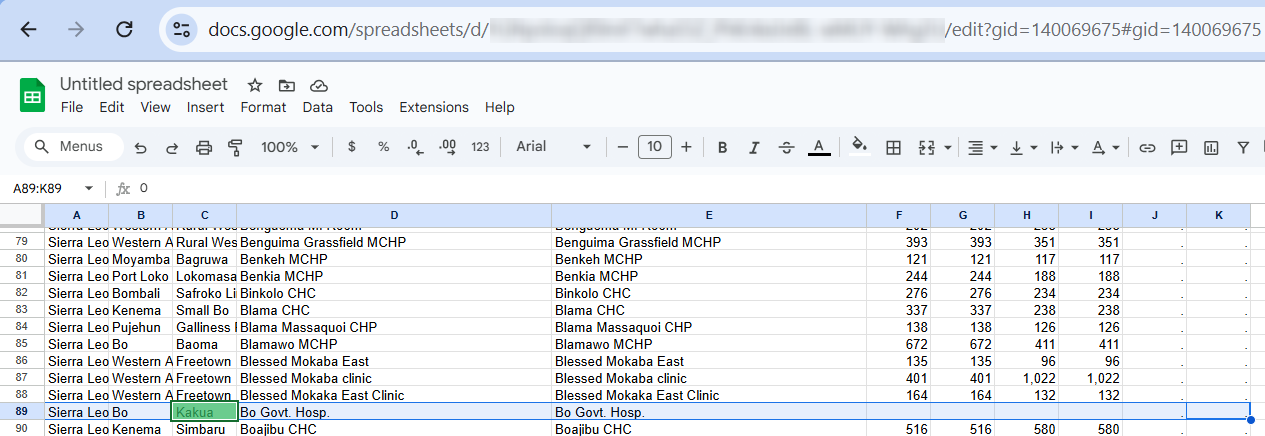
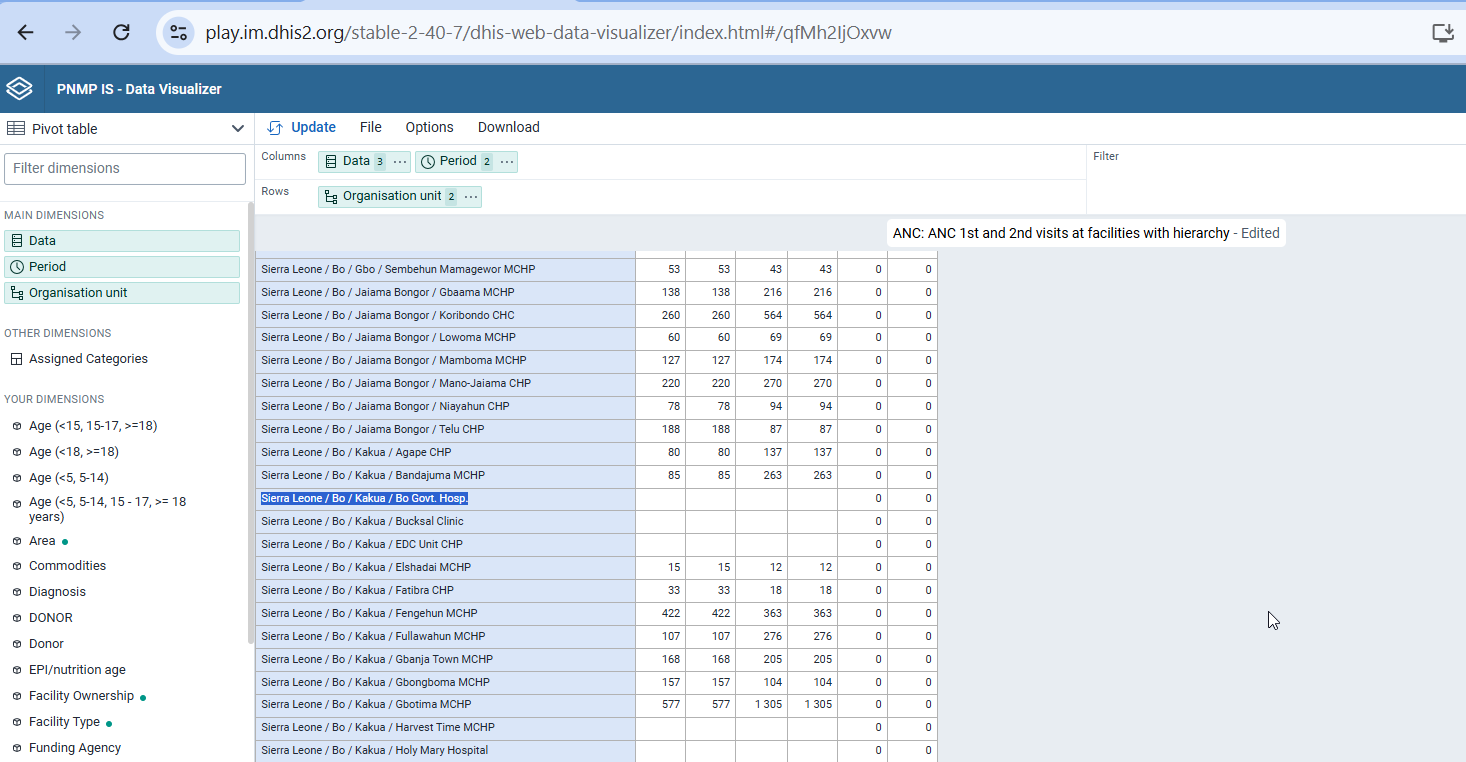
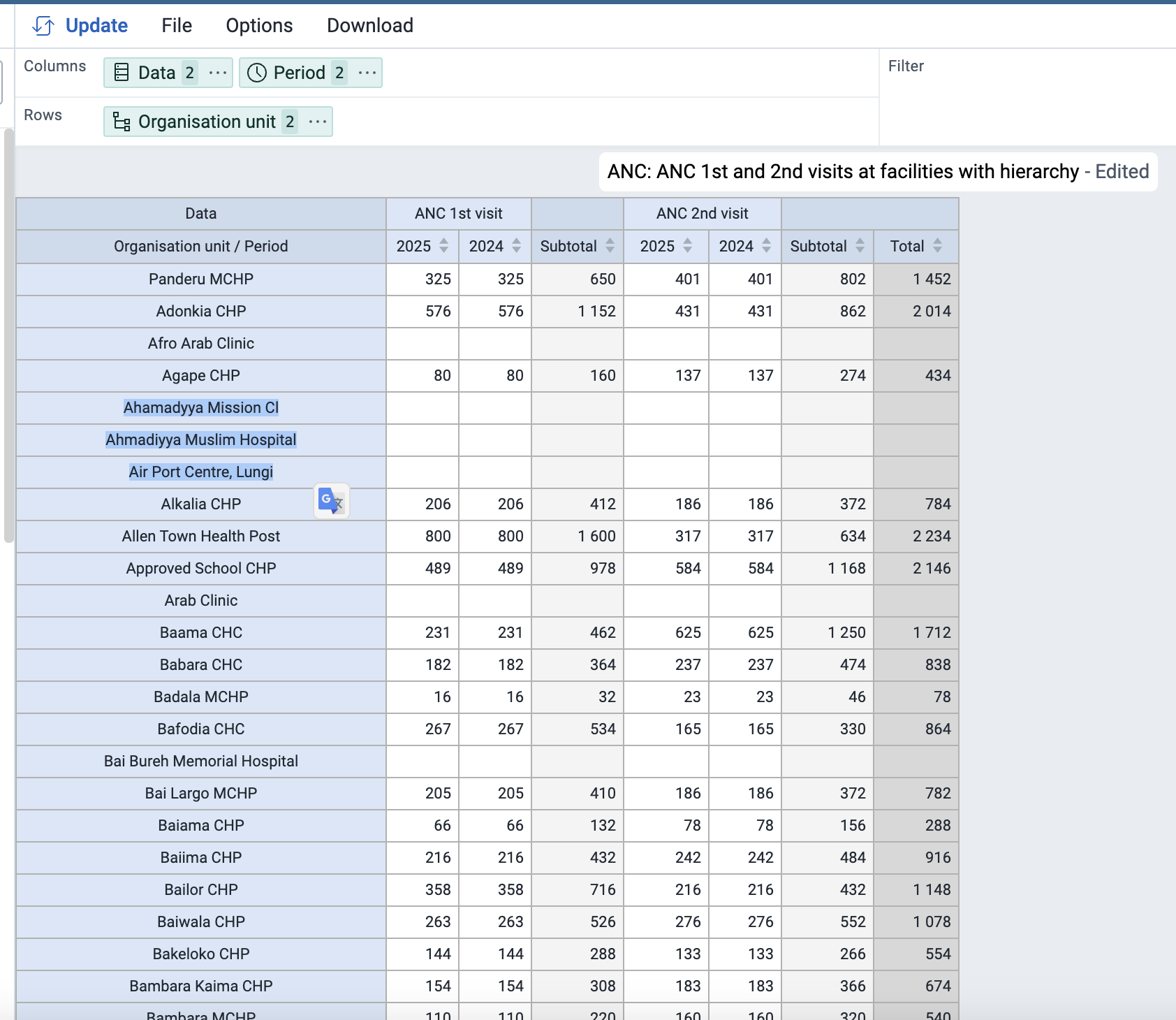
We are observing an issue while downloading xls/csv for pivot tables in data visualizer, for dhis2 versions>=2.39
Even when we have unchecked option of skip empty rows/columns, downloaded xls automatically removes empty rows/columns. This was not the case for <2.39 versions.
Do you know is there any JIRA associated with it? if not shall I raise one, also do we have any workarounds.
Oh, yes! I know what happened, thanks! When I was testing, I also added a calculation which add a ‘zero’ value thus resulting in no empty rows. Here’s what we can do:
Yes, please go ahead and create the Jira ticket. Thanks in advance!
Create a calculation with Number = 0. Delete the additional Calculation column after exporting to spreadsheet.
Hello
{
“app_name”: “Data Visualizer”,
“app_version”: “101.1.3”,
“dhis2_version”: “2.41.3”,
“dhis2_revision”: “9c942a6”
}
When we download an Excel file from the Data Visualizer application, it does not include the blank columns. This does not produce a unified file, as this file is used as a template. When blank columns are hidden, the template changes depending on the data. This is not what we want, as we did not select the option to hide blank columns from the options.
Also, for clarification, in previous versions, blank columns were not hidden when downloading an Excel file.
I don’t know why the recent dhis2 update has been causing so many problems.
Hi @Gassim , @edoardo mentioned that "we seem to pass correctly (we don’t pass it when not true) the option to the api, but the returned table always omits the empty.
From the API documentation the default value is false so all rows should be returned unless we pass hideEmptyRows=true in the request:
with hideEmptyRows=true ". But it seems not to be working on my side. @Eng.Ali_Hameed & @jthomas , were you able to resolve this issue?