The Aggregate Data Exchange Service (ADES) has been introduced in DHIS 2.39. It is a very promising tool as it’s an improvement over the t2a integration tool. Having developed similar implementations as scripts, I ran a few tests and have the following observations. If these are already implemented, it will be good to add them to the documentation.
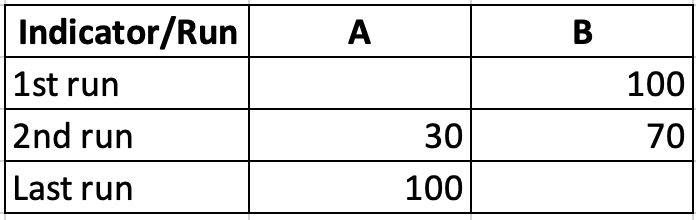
The ADES is missing a key component for tracker to aggregate integration: The ability to remove redundant values. For example, consider a cohort of 100 persons tracked majorly in two program indicators A (Active beneficiaries) and B (Inactive beneficiaries). We expect at the beginning of the implementation that all beneficiaries would be inactive (B = 100). As the implementation progresses, there would be more active beneficiaries until all beneficiaries are active (A = 100; B = 0). Note that if a program indicator evaluates to zero, it is not included in the payload.
Considering the table above, the first run will generate payload containing B only (A is zero). Second run will update B and import A.
The problem: The last run will only update A from 30 to 100, the value of B (70) remains in the system.
It will be useful to have the system check for any previously imported values not within the current payload, same way the predictors do. One other solution could be ability of program indicators to generate zero values (especially for TEI counts).
I see that this was raised in JIRA. I’m not sure if the optimisation has been implemented. It is noteworthy that this is not only peculiar to PIs but could also happen for aggregate to aggregate integration
For most of our implementations, varying COCs (within data elements) and AOCs (within data sets) are used for a large number of data elements (~ 200). It will be useful to have the ability to append generic dimensions within the source request, rather than having to specify each category dimension. For example ability to append"&dimension=co" and/or “&dimension=ao”.
See my new comment here in DHIS2-13105 about using predictors. I don’t believe the proposed new API endpoint has been implemented to delete values for a data set + org unit + period + attribute option combo, and I agree that is a good idea. I suggest that it include multiple values of periods and options for orgUnit descendants and wildcard AOCs.
In the absence of that, your idea for an option to store zero values for program indicator TEI counts also sounds reasonable to me although that might involve a database schema change as well as a frontend change so that might be more involved to do than the new API endpoint.
The option to ask for all co or ao values sounds very reasonable to me.
This is a great question and a use-case that we need to support. I see two main approaches.
Generate zero values in the source system and exchange with the target. The draw-back is that for a large country, at the facility level, we may generate a very high number of zero values which will have to be transferred. This will use a lot of bandwidth and make the export and the import processes slow.
Establish a concept of a “form import” with “replace” semantics, similar to HTTP PUT. For this concept, a client can define a form import as a combination of selected data sets, periods and org units, and decide to “replace” the existing data values. The most practical will be to do a delete operation for all data values, followed by an import.
The benefits is that the source request and data exchange payload will not be larger than what they currently are, and the import process will be efficient. The downside is that the audit trail/history of the data values is obfuscated, i.e. the audit trail will display a delete for every data exchange run.
The data exchange data model will have to be extended to allow for the “form import with replace” behavior. It is sort of a special case, but an important one, and a feature I think it makes sense to add.